
Foreword
Scholarly articles usually begin by providing a short historical narrative that gives readers the background necessary to contextualize the particular scholarly topic in question. So — given that my scholarly topic today is the modern-day potential of convolutional neural networks and their structures — I should theoretically begin by telling you about the authors of the very first artificial neural networks (ANNs), describing their inner structure, and further engaging you in smart-sounding but mostly empty dialogue about generally irrelevant but related topics. But that would be really boring for you. So I’m going to skip that part.
You should already understand — at least figuratively — the structure of the simplest ANN. Accordingly, by way of background material, let’s suffice with talking only about traditional neural networks (such as perceptron-type networks), which include only neurons and connections. To help you understand the concept, I’ll explain that a traditional neural network looks like a black box with one input and one output. It can be taught to reproduce the results of a certain function. We are not really interested in the architecture of our black box, however, since that architecture can vary widely for different cases and situations. What we are interested in is the following fact: all tasks solved by such traditional neural networks are regression (finding connection between the input and output data using already-existing examples) and classification (dividing the input data into several independent and non-overlapping sets).
Breakthrough
2002:
Earth Simulator, a supercomputer built by the Japanese in 2002, was one of the most powerful and fast computer complexes in the entire world. Until 2004, it was considered the most powerful computer complex in the world.
Price: $350,000,000
Size: Equivalent to four tennis courts
Productivity: 35,600 billion floating-point operations per second
2015:

The NVIDIA Tesla M40/M4 is a graphics processing unit (GPU) for neural networks. It is used for computer-aided learning.
Price: $5,000
Size: Fits in your pocket
Productivity: Up to 2,200 billion floating-point operations per second for all single-precision operations with NVIDIA GPU Boost™
The Ins and Outs of Convolutional Operation
The convolutional operation is one of the most resource-intensive theories (or, more precisely, methods) that requires exceptionally high levels of computational capacity. How does convolutional operation work? Let’s try to make it as simple as possible.
Cats

Neurophysiologists David Hubel and Torsten Wiesel were conducting experiments on cats when they discovered that similar parts of an image, as well as simple shapes, caused similar parts of the cats’ brains to become active. In other words, when a cat looks at a circle, the A-zone is activated in its brain. When it looks at a square, however, the brain’s B-zone is activated. These findings were used in their work on the principles of how visual systems function. Later, they confirmed these ideas with practical information.
Their conclusions sounded something like the following: animals’ brains contain a zone of neurons which react to the specific characteristics of an image. And each and every image passes through a so-called feature extractor before entering the deepest parts of the brain.
Mathematics
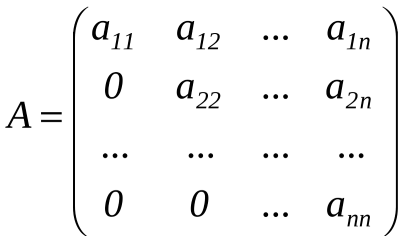
For a long time, graphic editors have been using matrix calculus to change image styles. Recently, it was discovered that the very same principles illustrated by our shape-watching cats can be used to recognize patterns.
For example, if we consider an image as a bi-dimensional pixel array, each pixel as a set of RGB values, and each value as an eight-bit byte, we’ll create a pretty traditional matrix. So let’s create our own matrix and call it our “kernel.” Our kernel matrix looks like this:

Next, let’s go through all of the positions — from the beginning to the end of the matrix of the image — and multiply our kernel by an area of similar size. The results will form the output matrix.
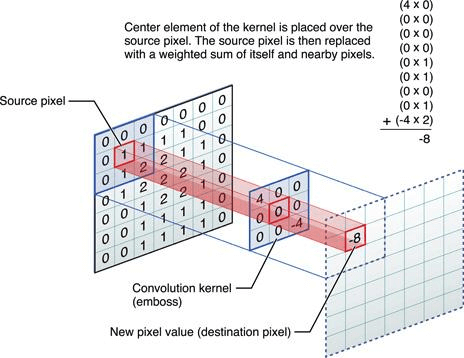
We will receive the following results:
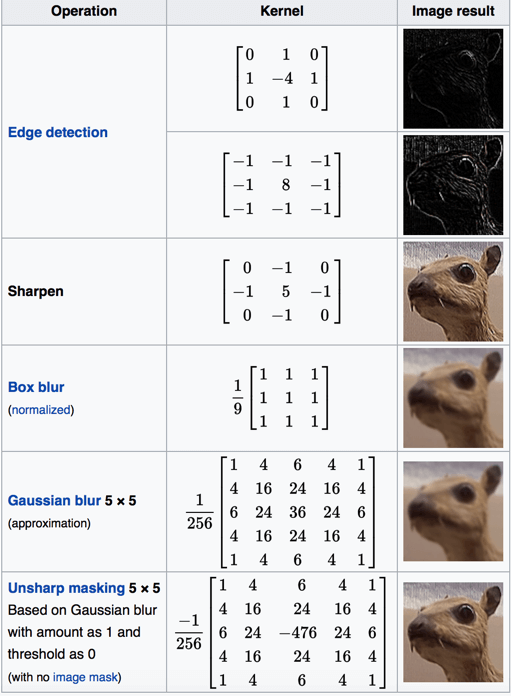
As we look at the “Edge detection” section, we can see that our results represent edges. In other words, we can find a kernel that will identify lines and curves with different directional properties. That’s exactly what we need — image features of the first level. Consequently, if we repeat the very same actions, we get a combination of the features of the first and the second levels (curves, circles, etc.). If we weren’t limited with our computing resources, we could repeat these actions many times.
Here’s an example of kernel matrices:

At the beginning, developers were trying to find kernel on their own. Ultimately they discovered that the desired results could be obtained using machine-aided cognition. The difficulty level of kernel increases from layer to layer. For example, kernel of the first layer is enough to find lines, edges, or curves. Kernel of the third layer can be used to discern text or divide typed and written symbols. Kernel of the fifth layer allows identification of details such as eyes, faces, animals, trees, and grass.
Pitfalls
Since we now knew the main principles of how the cat’s brain works, and we understood how to use the mathematical apparatus, we of course wanted to create our own feature extractor. However, after understanding the total number of required features and levels — and that in order to track complex shapes and characters, we would need to analyze all the features alongside each other — we realized that we wouldn’t have enough memory to hold all that data.
Mathematicians managed to solve this problem by inventing a pooling operation. Its central concept is very simple. If an area contains strongly expressed features, we can avoid searching for other features in that area.

This pooling operation not only allowed the saving of additional memory and computing resources, but also removed noise and artifacts from the image.
Practically speaking, developers alternate the convolution and pooling layers several times.
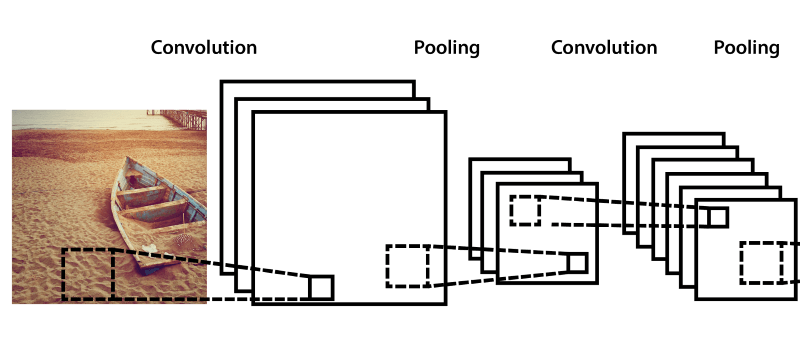
Final Architecture
After applying all the methods described above, we can create a feature extractor architecture that genuinely works. It will be no worse than the feature extractor at work in the brain of a cat. Furthermore, the recognition rate of the computer’s “vision” reached 98%. According to scientists, the average recognition rate of the human eye is 97%. (The future is already here, folks, and SkyNet is conquering the world.)
Below are several examples of real feature extractors.
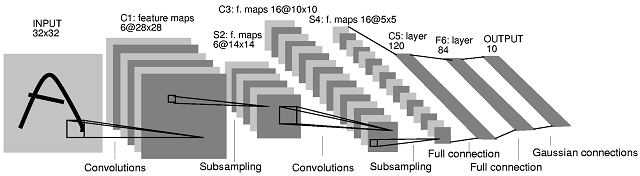


As you can see, there are two or three additional neural levels in each of these models. Such layers are not included in the feature extractor. These additional levels are for perception — i.e., the black box from the foreword. However, the black box’s input receives not only information about the colors of pixels (as in the simplest networks), but also information about the existence of an object that was used to train the feature extractor. You will agree that it’s easier to understand that you’re seeing a person’s face when you see a nose, a pair of eyes, a pair of ears, and hair than if someone is instead telling you the colors of each and every pixel that makes up the person’s face.
This video explains the main principles of feature extractors in an easy and understandable manner.
Leading the Pack in Computer Vision
Currently, there are several world leaders in the field of computer vision:
- TensorFlowTensorFlow is a free library for machine intelligence. Virtually all of Google’s smart services are based on it. Some people think that TensorFlow works only under *nix systems, but that’s incorrect. It also works with MacOS and Windows, although in Windows it’s a little harder to configure the environment.Below is an example of Inception-v3 (the Google image classifier based on TensorFlow) possibilities trained with a set of images from ImageNet.

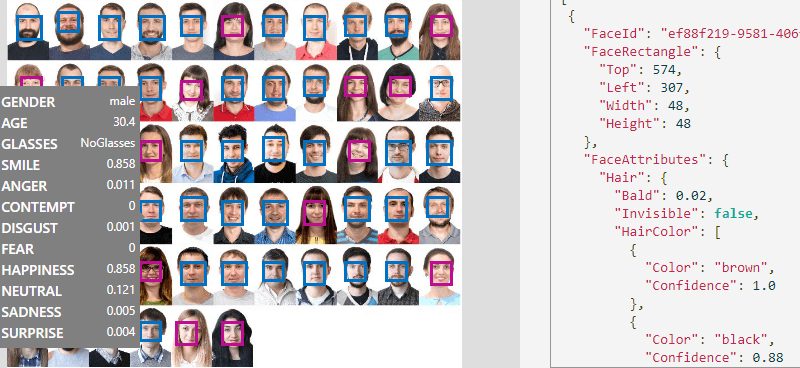
- MS Cognitive Services, or the Microsoft Cognitive Toolkit (MSCT)Microsoft decided to go another way. They provide predefined APIs commercially, as well as for free, limiting the number of requests in order to better see and understand how they work. There’s a wide selection of APIs that can solve dozens of tasks and problems. All of them can be tested right on Microsoft’s website.

Of course, we could use MSCT just as we use TensorFlow; they have fairly similar syntax and concepts. Both of them are describing graphs with placeholders. But why would we waste our time when we can use models that are already trained? - CaffeCaffe is an open framework that can be used to build any kind of architecture. Up until recently, it was the most popular framework. There are a huge number of free and ready-to-use (trained) network models that are based on this framework.Robert Bond developed a fairly spectacular system using Caffe implementation — a system which (ever so perfectly) brings us back to cats. Bond created a neural network trained with images of cats, using it to scare away all the neighborhood cats from his yard. When the system recognized the image of a cat, it turned on a sprinkler system for two minutes, dousing the cat with water. Anyone who knows how much cats hate water knows exactly how effective a system this would be.



There are a huge number of libraries, shells, and plugins which were popular in their time, including BidMach, Brainstorm, Kaldi, MatConvNet, MaxDNN, Deeplearning4j, Keras, Lasagne (Theano), and Leaf, but TensorFlow is now the most popular. TensorFlow has shown significant growth over the past two years.
Application Areas
| Scope | Comments | Links |
|---|---|---|
| Handwritten digits recognition | Human precision — 97.5% CNN — 99.8% |
Trained CNN Visualisation Play with CNN MNIST |
| Computer vision | CNN can recognize not only simple objects on a photo but emotions, actions, and also analyze video for a car driving (semantic segmentation) | Emotions Semantic segmentation Skype Caption bot Google Image Search |
| 3D reconstruction | Creates 3d models by video | Deep stereo |
| Art/Fun | Image style manipulations and generating photos by sketches | Deep dream Deep style Transfer style on video Generating faces Generating various things |
| Photo | Improving photo resolution and colorizing black & white images | Face Hallucination Colorizing |
| Medicine | Creating new medicines | |
| Security | Detecting abnormal behavior with Convolution and Recurrent networks | Abnormal detection Spatiotemporal detection Online camera detection |
| Gaming | At the end, NN plays better even than professional gamers | Atari Breakout |
Conclusion
Every day, information technology dives more deeply into our lives. Microprocessors spurred the technological revolution in the ‘70s, changing every facet of our lives that related to making calculations. Just 10 years ago, one could say that even though computers had become essential in our lives, they still weren’t able to beat out the human brain. After all, computers had no intuition, aesthetic sensitivity, or higher mental power. Today, however, convolutional neural networks are able to create music and pictures, discover diseases, and solve many other gargantuan tasks that were formerly considered to be exclusively anthropical — solvable only by mankind. At least we can count on the fact that the cats will never take over.
Would you like to learn more about how Distillery harnesses the power of machine intelligence to innovate product development? Let us know!

About the Author
Senior developer Roman Veremyov seems to have been with Distillery forever. When he joined the company in 2009, he already had vast experience in web development. At the age of 14, he wrote his first program – a racing game – using the QBasic programming language. Roman is a huge fan of fishing. His current personal record is a 21-pound carp.